VERSION SPACES AND THE CANDIDATE-ELIMINATION ALGORITHM
•
The key idea in the CANDIDATE-ELIMINATION algorithm is to output
•
a description of the set of all hypotheses consistent with the training examples

Note difference
between definitions of consistent and satisfies
· An example x is said to satisfy hypothesis h when h(x) = 1, regardless of whether x is a positive or negative example of the target concept.
· An example x is said to consistent with hypothesis h iff h(x) = c(x)


The LIST-THEN-ELIMINATION algorithm
The LIST-THEN-ELIMINATE algorithm first initializes the version space to
contain all hypotheses in H and then eliminates any hypothesis found
inconsistent with any training example.
___________________________________________________________________________
1. VersionSpace c a list containing every hypothesis
in H
2. For each training example, (x, c(x))
remove from VersionSpace any hypothesis h for which
h(x ≠ c(x)
3. Output the list of hypotheses in VersionSpace
_________________________________________________________________________
The LIST-THEN-ELIMINATE Algorithm
·
List-Then-Eliminate works in principle, so long as version space is finite.
·
However, since it requires exhaustive enumeration of all
hypotheses in practice it is not feasible
Consistent Hypothesis and Version Space
•
F1 - > A, B
•
F2 - > X, Y
•
Instance Space: (A, X), (A,
Y), (B, X), (B, Y) – 4 Examples
•
Hypothesis Space: (A, X), (A,
Y), (A, ø), (A, ?), (B, X), (B, Y), (B, ø), (B, ?), (ø,
X), (ø, Y), (ø, ø), (ø, ?), (?, X), (?,
Y), (?, ø), (?, ?) - 16 Hypothesis
•
Semantically Distinct Hypothesis: (A,
X), (A, Y), (A, ?), (B, X), (B, Y), (B, ?), (?, X), (?, Y ), (?,
?), (ø, ø) – 10
Version Space: (A, X), (A,
Y), (A, ?), (B, X), (B, Y), (B, ?), (?, X), (?, Y) (?, ?), (ø, ø),
•Training
Instances
F1 F2
Target
A X
Yes
A Y
Yes
•Consistent
Hypothesis are: (A, ?), (?, ?)
List-Then-Eliminate algorithm
•
Problems
ü The
hypothesis space must be finite
ü
Enumeration of all the hypothesis, rather
inefficient
A More Compact Representation for
Version Spaces
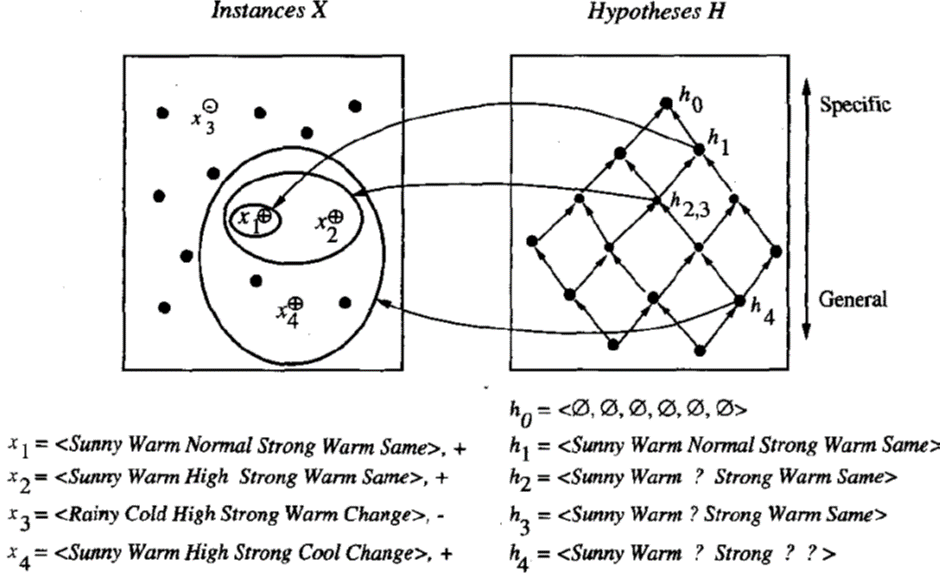
• The version space is represented by its most general and least general members.
• These members form general and specific boundary sets that delimit the version space within the partially ordered hypothesis space.





·
A version space with its general and specific
boundary sets.
·
The version space includes all six hypotheses shown
here, but can be represented more simply by S and G.
·
Arrows indicate instances of the more_general_than
relation.
·
This is the version space for the EnjoySport
concept learning problem and training example.
CANDIDATE-ELIMINATION Learning Algorithm
The CANDIDATE-ELIMINTION algorithm computes the version
space containing all
hypotheses from H that are consistent with an observed
sequence of training examples.
___________________________________________________________________________
Initialize
G to the set of maximally general hypotheses in H
Initialize
S to the set of maximally specific hypotheses in H
For
each training example d, do
• If d is a positive example
• Remove from G any hypothesis
inconsistent with d
• For each hypothesis s
in S that is not consistent with d
• Remove s from S
• Add to S all
minimal generalizations h of s such that
• h is consistent with d,
and some member of G is more general than h
• Remove from S any
hypothesis that is more general than another hypothesis in S
• If d is a negative example
• Remove from S any
hypothesis inconsistent with d
• For each hypothesis g in
G that is not consistent with d
• Remove g from G
• Add to G all minimal
specializations h of g such that
• h is consistent with d,
and some member of S is more specific than h
•
Remove from G any hypothesis that is less general than another hypothesis in G
___________________________________________________________________________
CANDIDATE- ELIMINTION algorithm using version spaces
An
Illustrative Example

CANDIDATE-ELIMINTION algorithm begins by initializing the
version space to the set of all hypotheses in H;
•
Initializing the G boundary set to contain the most general hypothesis in H
•
Initializing the S boundary set to contain the most specific (least general) hypothesis
ü When the first training example
is presented, the CANDIDATE-ELIMINTION algorithm checks the S boundary and finds that it is overly specific
and it fails to cover the positive example.
ü The boundary is therefore
revised by moving it to the least more general hypothesis that covers
this new example
ü No update of the G
boundary is needed in response to this training example because Go
correctly covers this example.

When the second training example is observed, it has a similar effect of generalizing S further to S2, leaving G again unchanged i.e., G2 = G1 =G0

·
Consider the third training example. This negative example reveals
that the G boundary of the version space is overly general, that is, the
hypothesis in G incorrectly predicts that this new example is a positive
example.
·
The hypothesis in the G
boundary must therefore be specialized until it correctly classifies this new
negative example

Given that there are six attributes that could be
specified to specialize G2, why are there only three new hypotheses in G3?
· For example, the hypothesis h = (?, ?, Normal, ?, ?, ?) is a minimal specialization of G2 that correctly labels the new example as a negative example, but it is not included in G3.
· The reason this hypothesis is excluded is that it is inconsistent with the previously encountered positive examples
Consider the fourth training example:

•
This positive example further generalizes the S boundary of the
version space. It also results in removing one member of the G boundary,
because this member fails to cover the new positive example
•
After processing these four examples, the boundary sets S4 and G4
delimit the version space of all
hypotheses consistent with the set of incrementally observed training
examples.