Convolutional Neural Network 1
Q1. CNN features
Why is convolution neural network taking off quickly in
recent times?
Choose the correct answer from below:
A. Access to large amount of digitized data
B. Integration of feature extraction within the training process
C. Availability of more computational power
D. All the above
Ans:
- All
the above is the correct answer.
- Using
CNN, we can Access and train our model on a large amount of digitized data
- Unlike
classical image D recognition where you define the image features
yourself, CNN takes the image’s raw pixel data, trains the model, then
extracts the features automatically for better classification.
- Using
CNN, the number of training parameters is reduced significantly. And due
to the availability of more computational power in recent times. The model
takes less time to train.
Q2. Recognizing a cat
For an image recognition problem (recognizing a cat in a
photo), which of the following architecture of neural network would be best
suited to solve the problem?
Choose the correct answer from below:
A. Multi Layer Perceptron
B. Convolutional Neural Network
C. Perceptron
D. Support Vector Machine
Ans: B
The correct answer is Convolutional Neural Network.
The Convolutional Neural Network (CNN or ConvNet) is a subtype of the Neural
Networks that is mainly used for applications in image and speech recognition.
Its built-in convolutional layer reduces the high dimensionality of images
without losing its information. That is why CNNs are especially suited for this
use case.
Q3. CNN Layers
Which of the following statements is False?
Choose the correct answer from below:
A. CNN's are prone to overfitting because of less number of parameters
B. There are no learnable parameters in Pooling layers
C. In a max-pooling layer, the unit that contributes(maximum entry) in the forward propagation gets all the gradient in the backpropagation
D. None of the above
Ans: A
Correct option: CNNs are prone to overfitting
because of less number of parameters
Explanation :
- The
statement "CNNs are prone to overfitting because of less number of
parameters" is false. CNN's are prone to overfitting when they have a
lot of parameters. A neural network with a lot of parameters tries to
learn too much or too many details in the training data along with the
noise from the training data, which results in poor performance on unseen
or test datasets, which is termed overfitting.
- There
are no trainable parameters in a max-pooling layer. In the forward pass,
it passes the maximum value within each filter to the next layer. In the
backward pass, it propagates error in the next layer to the place from
where the max value is taken, because that's where the error comes from.
You can use this link to
learn more about max pooling layer.
- In
a max-pooling layer, the unit that gets contributed(maximum entry) in the
forward propagation gets all the gradients in the backpropagation.( This
is True )
Q4. Max-Pooling necessary
Why do we use Max-pooling in Convolutional Neural Networks ?
Choose the correct answer from below, please note that
this question may have multiple correct answers
A. Reduce Resolution
B. Extract the High intensity features
C. Extract the low intensity features
D. Increase Resolution
Ans: A, C
The correct answers are:
- Reduce
Resolution
- Extract
the High intensity features
Reason:
- Max-pooling
helps in extracting high intensity features.
- While
Avg-pooling goes for smooth features.
- If
time constraint is not a problem, then one can skip the pooling layer and
use a convolutional layer to do the same.
- It
also helps in reducing the resolution of the input.
Q5. Pixel
A Pixel means a Picture Element. It is the smallest Element
of an image on a computer display. Given two different images (pixel grids,
where cells have the value of pixels) of size 5×5, find out the type of image1
and image2 respectively.
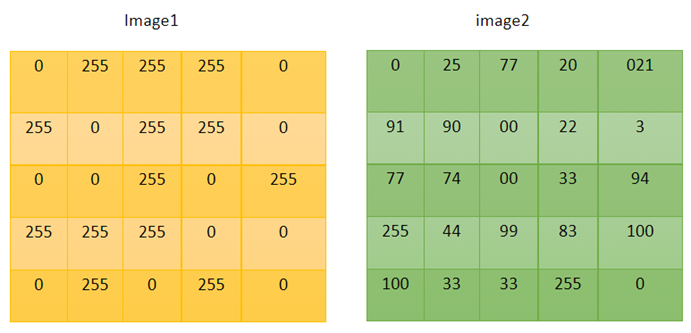
Choose the correct answer from below:
A. image1= Black and White, image2= color
B. image1= color, image2= Black and White
C. image1= Grayscale, image2= color
D. image1= Black and White, image2= Grayscale
Ans: D
- Correct
answer is image1= Black and White, image2= Grayscale
- For
a binary image (Black and White), a pixel can only take a value of 0
or 255
- In
a GrayScale image, it can choose values between 0 and 255.
Q6. Translation in-variance
Determine whether the given statement is true or false.
When a pooling layer is added to a convolutional neural network, translation
invariance is preserved.
Note: Translation in-variance means that the system produces the same
response, regardless of how its input is shifted.
Choose the correct answer from below:
A. True
B. False
Ans: A
The correct answer is True
Reason:
- Invariance
means that we can recognize an object as an object, even when its
appearance varies in some way. This is generally a good thing, because it
preserves the object's identity, category, (etc.) across changes in the
specifics of the visual input, like relative positions of the
viewer/camera and the object.
- Pooling
helps make the representation approximately invariant to small
translations of the input.
• If we translate the input by a small amount, the values of most of the outputs do not change.
• Pooling can be viewed as adding a strong prior that the function the layer learns must be invariant to small translations.
Q7. True About Type of
Padding
Which of the following are True about Padding in CNN?
Choose the correct answer from below, please note that
this question may have multiple correct answers
A. We should use valid padding if we know that information at edges is not that much useful.
B. There is no reduction in dimension when we use zero padding.
C. In valid padding, we drop the part of the image where the filter does not fit.
Ans: A,B,C
The correct answers are:
- We
should use valid padding if we know that information at edges is not that
much useful.
- There
is no reduction in dimension when we use zero padding.
- In
valid padding, we drop the part of the image where the filter does not
fit.
Reason:
- The
output size of the convolutional layer shrinks depending on the input size
& kernel size.
- In
zero padding, we pad zeros around the image's border to save most of the
information, whereas, in valid padding, we lose out on the information
that doesn't fit in filters.
- There
is no reduction in dimension when we use zero padding.
- To
sum up, Valid padding means no padding. The output size of the
convolutional layer shrinks depending on the input size & kernel size.
On the contrary, 'zero' padding means using padding.
Q8. CNN with benefits
What are the benefits of using Convolutional Neural
Network(CNN) instead of Artificial Neural Network(ANN)?
Choose the correct answer from below, please note that
this question may have multiple correct answers
A. Reduce the number of units in the network, which means fewer parameters to learn and decreased computational power is required
B. Increase the number of units in the network, which means more parameters to learn and increase chance of overfitting.
C. They consider the context information in the small neighborhoods.
D. CNN uses weight sharing technique
Ans: A, C,D
Correct options:
- Reduce
the number of units in the network, which means fewer parameters to learn
and decreased computational power is required
- They
consider the context information in the small neighborhoods
- CNN
uses weight sharing technique.
Explanation :
- CNNs
usually have a lesser no of parameters compared to ANNs, which means
- CNNs
consider the context information and pixel dependencies in the small
neighborhood and due to this feature, they achieve a better prediction in
data like images
- Weight
sharing decreases the number of parameters and also makes feature search
insensitive to feature location in the image. This results in a more
generalized model and thus also works as a regularization technique .
Q9. Appyling Max pooling
If we pass a 2×2 max-pooling filter over the given input
with a stride of 2, find the value of W, X, Y, Z?

Choose the correct answer from below:
A. W = 8, X = 6, Y= 9, Z=6
B. W = 9, X = 8, Y= 8, Z=6
C. W = 6, X = 9, Y= 8, Z=8
D. W = 9, X = 8, Y= 8, Z=9
Ans: B
The correct answer is W = 9, X = 8, Y= 8, Z=6

- Our
first 2 × 2 region is highlighted in yellow, and we can see the max value
of this region is 6.
- Next
2 × 2 region is highlighted in blue, and we can see the max value of this
region is 9.
- Similarly,
we will do this for all the 2×2 sub-matrices highlighted in different
colors.
Q10. Difference in output
size
What is the difference between the output size of the given
two models with input image of size 100×100. Given, number of filter, filter
size, strides respectively in the figure ? (Take padding = 0)

Note: The Answer is the difference of final convolution of Model1 and
Model2.
Example: Say the final convolution of Model1 is 10 x 10 x 30 = 3000
and Model2 is 20 x 20 x 14 = 5600
Answer = 5600 - 3000 = 2600
Choose the correct answer from below:
A.
1392
B.
1024
C.
6876
D.
500
Ans: B
The correct answer is 1024
The result size of a convolution after 1 layer will be (W – F + 2P) /S + 1.
For model 1,
Step1 - Input = 100 x 100, filter = 15, filter size = 3 x 3,
strides = 1
Answer = (100 - 3 + (2x0))/1 + 1 = 98
Step1_output = 98 x 98 x 15
Step2 - Input = 98 x 98, filter = 42, filter size = 6 x 6, strides
= 4
Answer = (98 - 6 + (2x0))/4 + 1 = 24
Step2_output = 24 x 24 x 42
Step3 - Input = 24 x 24, filter = 30, filter size = 3 x 3, strides
= 3
Answer = (24 - 3 + (2x0))/3 + 1 = 8
Step3_output = 8 x 8 x 30
final_model1_ output = 1920
——————————————————————————
For model 2,
Step1 - Input = 100 x 100, filter = 5, filter size = 6 x 6, strides
= 1
Answer = (100 - 6 + (2x0))/1 + 1 = 95
Step1_output = 95 x 95 x 5
Step2 - Input = 95 x 95, filter = 11, filter size = 3 x 3, strides
= 4
Answer = (95 - 3 + (2x0))/4 + 1 = 24
Step2_output = 24 x 24 x 11
Step3 - Input = 24 x 24, filter = 14, filter size = 3 x 3, strides
= 3
Answer = (24 - 3 + (2x0))/3 + 1 = 8
Step3_output = 8 x 8 x 14
final_model2_ output = 896
Therefore, difference in output size will be 1920 – 896
= 1024.
Q11. Horizontal Edges
Perform a default Horizontal edge detection on the given
image and choose the correct option?
Note : Here Stride = 1, Padding = Valid


Choose the correct answer from below:
A.
A
B.
B
C.
C
D.
D
Ans: A

Therefore, correct option is A
Q12. Dimensionality
Reduction
Jay is working on an image resizing algorithm. He wants to
reduce the dimensions of an image, he takes inspiration from the course he took
on Scaler related to Data Science where he was taught about CNN's. Which of
these options might be useful in the dimensionality reduction of an image?
hoose the correct answer from below, please note that
this question may have multiple correct answers
A.
Convolution Layer
B.
ReLU Layer
C.
Sigmoid
D.
Pooling Layer
Ans: A,D
Correct options:
- Convolution
Layer
- Pooling
Layer
Explanation :
- Convolution
Layer helps in dimensionality reduction as convolution layer can decrease
the size of input depending upon size of kernel, stride etc.
- Pooling
layer also decreases size, like if we use Max Pooling, then it takes
maximum value present in size of kernel matrix.
- ReLU
and sigmoid are just activations, they don't affect the shape of an image.

Comments
Post a Comment